November 5, 2021
PxDB is an application API server, designed to connect to an arbitrary number of SQL database backends and automatically reflect their schemas into GraphQL schemas, serving the GraphQL schemas as web service APIs. The GraphQL schemas include a regular, standardized set of parameters which offer robust and complex filtering, ordering, and paging of queries, as well as automatically generated mutations to create, update, and delete records. PxDB is designed to ease the development of networked applications by automating API generation, providing built-in user management, enforcing security policies, offering programmable server-side extensibility, and for web applications, automatically generating client-side data models.
Queries, in particular, are filtered using an expression language, based on (but not entirely like) SQL “WHERE clause” syntax. This syntax allows complex queries based on more than just equality comparisons; various comparison and mathematical operators, list membership lookups, and even (limited, whitelisted) database functions may be used. In some cases, the syntax has been simplified from SQL standard, so that, e.g., “createdate = max(createdate)” is a valid expression for getting the most recently created record, whereas it would not be valid SQL in a WHERE clause without a subselect. The expressions are not passed directly to a SQL backend, but are parsed using a LALR(1)1 parser, and the results applied programmatically to create a valid, and safe, SQL query. The risk of SQL injection attacks is thus eliminated.
PxDB offers a built-in user and group (“role”) management system, independent of the database schemas themselves. Roles can be created in hierarchies, or can be grouped together into non-hierarchical “role classes”, or both, as administrators see fit. Roles and role classes are key to organizing users, and also to granting access, using PxDB’s security system.
This security system is based on a relatively new theoretical foundation, known as Attribute-Based Access Control, or (as we prefer to call it) Policy-Based Access Control.2 PBAC, as we term it, defines access based on a set of rules which define how various roles and/or role classes can access tables, views, and other exported objects in a given database. These rules are effectively logical expressions based on attributes of the role, role class, operation, and target table or records within the table; when evaluated, if the rule returns “true”, access is granted. Policy rules implement “filters” based on the same expression language used for query filtering.
PBAC provides a powerful and flexible means of defining security policies, without the combinatorial explosion of entries inherent in the classic access control list, or the similar issue of role proliferation in standard role-based access control (RBAC). PBAC policies can implement both mandatory and discretionary access controls, as well as RBAC, using policy rules.
PxDB is multi-tenant by design; each database is considered a separate “tenant” for organizational purposes. Each tenant has its own schema, roles, role classes, and policy rules. Furthermore, as long as the database systems used are compatible with PxDB’s backend, there is no restriction on which Relational Database Management System (RDBMS) a tenant lives on; PxDB can, and has, connected to multiple RDBMS instances at once to serve up APIs. Tenancies can live on Oracle DBMS, Microsoft SQL Server (and Azure SQL), MySQL and MariaDB, PostgreSQL, or even SQLite. 3
PxDB will support inter-tenant queries, using our “Advanced Connectivity” package. This will provide a means for roles in one tenant to query objects in another tenant; the “host” tenant will determine the policy for the “guest” access, and the “guest” roles, in turn, will be limited by their own policy in which parts of the “foreign” data they can access. This feature is currently in the design phase.
In addition to its support for the standard Create, Read, Update, and Delete operations needed in a web API, user management, and security system, PxDB also comes with extensions known as packages. Functionality is grouped into packages in order to allow enabling that functionality for various tenants, and for billing purposes, if desired.
Packages enhance PxDB’s capabilities in a number of ways, such as:
Associating table records with files stored in a file storage backend, such as a cloud storage provider
Geospatial capabilities, including storing and querying geospatial data and rendering it via standard OpenGeospatial Web Services (OWS)
Image and multimedia processing
Cross-database querying and access mediated via policies
Analytical functions and queries
Financial transaction handling via the BNG payments API
Sending of email and SMS notifications
PDF report generation based on templates
The system can be further extended using the built-in “process rule” engine. This engine allows adminstrators to create rules that run a Python program when mutations occur on a target table; conceptually, this is like a database trigger, but is far more capable, as the Python program can perform any operation desired. Process rule programs are designed to be generic, with much of their behavior determined by parameters stored in the database; the same program can thus be run by several different rules and produce very different results. Because process rule programs would be a major security risk if they could be configured by external users, PxDB only allows process rules to be created by installation administrators on behalf of tenants.
To ease development of web or Node.js applications, PxDB also comes with an associated Javascript library, PXDB.js. This library uses GraphQL schema introspect and Javascript metaclass code generation to create Backbone model and collection classes for GraphQL schema objects, with models corresponding to individual rows, and collections corresponding to tables or views. These automatically generated classes come with built-in methods for query filtering, ordering, and paging, as well as validations for mutations. In the future, a newer version of PXDB.js will provide automatic generation of Redux sagas, for use with React components.
With this client library, a Javascript developer effectively has the ability to code to the database schema; from the database to the web application, PxDB server and client software provides end-to-end reflection and automatic code generation to handle data transport.
The end result is that, with PxDB, a set of databases can be turned into web-ready API endpoints in a matter of hours: a few minutes to introspect the databases, and then the time needed to design and implement the security policy and roles for each tenant. Most of this work is business-logic decisions, not coding time; developers can thus spend their time writing the application.
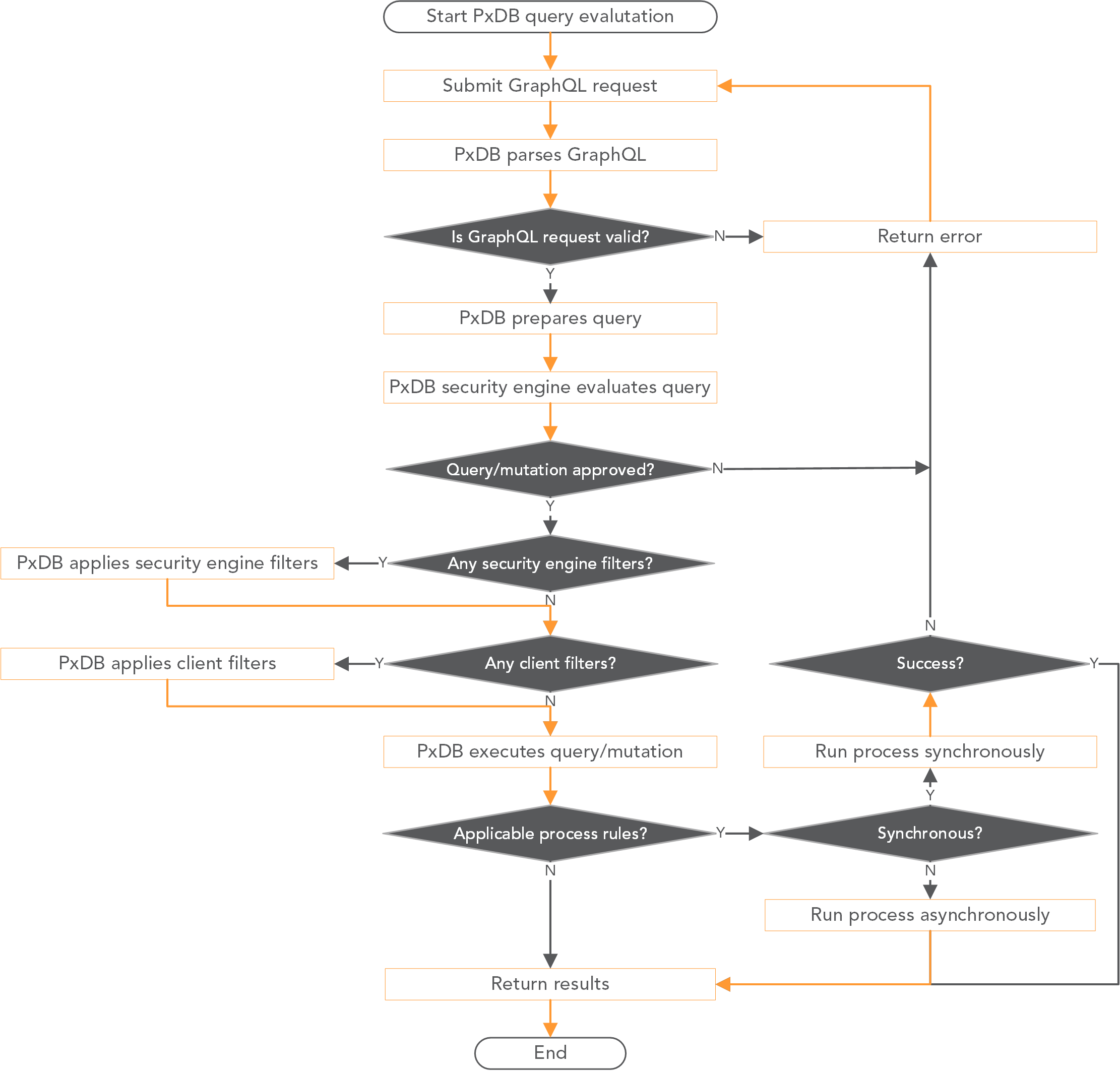
PxDB consists of two containers: the main API server container, and a separate “process runner” which handles background tasks and running process rule jobs. The API server is implemented as a single-process program which runs behind the Web Server Gateway Interface (WSGI) service broker uWSGI, and evaluates each GraphQL query or mutation according to the following process:
A GraphQL request is submitted to the API endpoint.
PxDB parses the GraphQL and validates it according to the defined schema. Syntax errors are caught at this time, as well as references to invalid types or fields. If the GraphQL is invalid, an error is signalled.
PxDB prepares a query or mutation object to handle the request.
PxDB’s security engine looks for policy rules which allow the query or mutation to proceed. For a query, a rule being present means that the query can proceed, though the rule’s filters may prevent results from being returned; this is not considered an error. For mutations, a rule filter acts as a constraint, and trying to mutate a record that doesn’t match the filter will trigger an error.
In cases where multiple rules may allow a query or mutation to proceed, the rule engine selects the most specific rule: rules for specific roles first, then for role classes, then rules with only one target table, then rules with multiple target tables. If one applicable rule has a filter and the other does not, the rule without the filter is used. If multiple rules with filters are applicable, an error is signalled. (This is a very rare case, and good policy design should prevent it from ever occurring.)
If the client passed in a filter expression, ordering specifications, or paging instructions (limit and offset), these are applied after any policy rule filters. The filter expression is parsed by the expression parser, and if valid, applied to the query. Invalid expressions trigger an error.
The query or mutation itself is executed. What happens then depends on the type of operation being executed:
In the case of a query, the results are then returned immediately.
For a mutation, PxDB checks if the target table has any process rules which are applicable to this operation. If there are none, the results of the mutation are returned.
In the case where there are process rules that apply, PxDB must determine if they are synchronous or asynchronous processes. Synchronous processes cause PxDB to wait for the process result before returning, and in the case where a synchronous process fails (e.g., payment is declined), PxDB will fail the transaction and signal an error. The mutation that would otherwise occur is aborted. Synchronous rules should only be used for relatively quick operations, such as financial transactions, where success or failure of the whole mutation depends on the process succeeding or failing.
Asynchronous rules, on the other hand, can be run independently; PxDB will signal the process runner to start the processes, but will not wait for completion, and will return the mutation results immediately. Asynchronous process rules are suitable for longer-running “batch” work, where something needs to be done based on the data that has been added, updated, or removed, but the results are not needed immediately, and the mutation itself can be allowed to complete without the process being finished.
PxDB consists of a set of core features, “PxDB Core”, with additional functionality available in “packages”. PxDB Core is responsible for the basic GraphQL schema generation, querying, and mutation, as well as handling of tenants, roles, role classes, and policy rules. It is Core that does the basic work of presenting the API for each tenant. Core also contains the parser and evaluator for the expression language used in query filtering and policy rules.
Beyond this, the following packages have been implemented, offering additional functionality:
Multimedia: Associates files stored in a backing file store with table records. At the GraphQL API layer, this appears as though the files are “stored on” the record; the files are presented for download using signed URLs. New file associations are similarly presented for upload as signed upload URLs. This is implemented using the Cloudstorage library. The backing file store can be a cloud storage system, such as Azure Blob Storage, Google Cloud Storage, Amazon S3, or it can be an on-premises file storage system.
Geospatial: Adds geospatial data types (geometry and geography) to those exposed via GraphQL and makes geospatial functions available for use in query filters. Geometry types are represented as sub-types on the record, with fields representing their attributes such as spatial reference identifier, geometry in OGC Well-Known Text format, centroid, and envelope (bounding box). Geospatial queries can make use of geospatial functions exposed in the API via a whitelist.
Geoimaging: Leverages capabilities of the multimedia and geospatial packages to allow rendering geospatial rasters, as well as performing image processing. This is implemented using the process rules engine.
Alerts: Allows for notifications to be sent out via email or SMS when changes occur to a given table. This is implemented using process rules.
Reporting: Generation of formatted and styled HTML/PDF reports, using templates written using Javascript. This is implemented using process rules.
Financials: Allows for mutations to require payment via a payment gateway processor; our initial choice is the NMI-compatible API from BNG Holdings, Inc. The Financials package enables the purchase of content (database or file) via the PxDB API, running credit card or electronic check transactions for purchases of physical goods for a point-of-sale system, as well as saving payment methods and setting up recurring subscriptions. This uses process rules.
Aggregate queries: Server-side aggregates can be called on tables or views, returning JSON results. The aggregates may be run on a filtered subset of a table, using the expression language to perform filtering, and may be grouped by other columns in the table. The exported aggregates are currently avg, count, max, min, and sum; other to be added later, as needed.
Function and procedure calls: Database functions which return values or sets, and stored procedures, may be exported through the GraphQL API, with access control provided by the policy rule engine. This allows for complex internal logic to be stored in the database and called externally, rather than requiring that logic to live in the application; any application that would make use of database functions can leverage this feature.
Future packages:
Analytics: OLAP-style query functionality. Window functions, grouping sets, ROLLUP, and CUBE will be available. This will be implemented using the function whitelist and extensions to the expression language syntax, as well as providing additional autogenerated fields on GraphQL types. This is a planned, but currently unscheduled, feature.
Advanced Connectivity: Cross-tenant interaction, where a role in one tenant can query tables from another, according to both local and remote policy rules. This will use two new concepts: the host tenant (who is exposing some of their tables) will create “foreign roles”, at least one for each tenant who is to have guest access to their schema; and then the guest tenants will have a “gateway” object that will expose the foreign tables in their schema. This will be implemented using a combination of policy and role extensions. This is a feature in the concept stage, but development will depend on customer demand.
PxDB requires one database for itself, which it uses for system tables. These system tables store such information as tenants, roles, role classes, policy rules, process rules, and various other system information. This database can be named anything, though “pxdb” is generally a good choice; this is configurable in the pxdb.conf configuration file. This database must grant full access to PxDB, for it to create and manage the system tables.
PxDB is designed to be a container-based server application, running in Docker containers orchestrated by Kubernetes. Runtime information such as the configuration file, public and private key for JSON Web Token generation, and access keys for cloud storage backends are stored as Kubernetes secrets.
PxDB is not a web server; it is a WSGI application, which needs a web server in front of it. Our installation uses a Kubernetes ingress with nginx as its web server; other web servers should work as well, as long as they are capable of interfacing with WSGI applications.
Our purpose in building PxDB was, first and foremost, to support our own application development; however, we had always envisioned that PxDB could itself be a product, in addition to supporting our apps as products. Thus, whenever possible, we aim for generality, automation, flexibility, and configurability. That said, there were a few ways in which we had to restrict our focus, in order to create a usable system.
We limited our supported data storage backends to SQL databases, specifically those supported out of the box by Python’s SQLAlchemy library: MySQL, PostgreSQL, Oracle, Microsoft SQL Server, and SQLite. These constitute the “big four” of the SQL RDBMS market, plus the most popular embedded SQL database format. SQL databases not supported by default, but for which SQLAlchemy has drivers, are available on request, but we do not package drivers for them by default.
We have no plans to support “NoSQL” databases such as MongoDB, CouchDB, Redis, etc. This is for three reasons.
First, SQL’s relational character, with its primary and foreign keys, allows for easy generation of relationships in GraphQL schemas. Those relationships would have to be hand-coded in a NoSQL schema, as most NoSQL databases do not have a means of representing relationships, and those that do, do so in their own idiosyncratic way.
Second, SQL databases have a regularity, based on their use of a standardized query language, that allows creation of a single backend library to communicate with them. SQLAlchemy is such a backend library, and is able to leverage the commonalities in SQL systems and handle the relatively minor differences between dialects. To support a variety of SQL database backends, all we have to do is use SQLAlchemy and install the appropriate drivers.
By contrast, each NoSQL database has its own query language or API; efforts such as JSONiq to create a standardized query language for NoSQL have not been very successful. To support each NoSQL database, we would have to add new code with a new library, which would require a great deal more coding time and effort.
The final reason is that most NoSQL systems do not have a defined schema for their data. The lack of schema makes for a dynamic data storage backend, but is unsuitable for automatically generating a GraphQL schema. If any record could store any set of values, how can types be introspected and generated? A lack of defined schema makes any stored data uninterpretable, beyond what its original application intended; this is very similar, ironically, to the problems inherent in old COBOL database files, where the data was unreadable without having the original COBOL source’s “data dictionary” that defined the record fields.
LALR(1) parsers are described in further detail at Wikipedia; see the article’s references list for further information.↩︎
For further reading on the theoretical basis of ABAC/PBAC, this paper by Xin Jin, Ram Krishnan, and Ravi Sandhu is a good starting point. That said, our implementation is not precisely like the one described in their paper: they discuss using an XML-based syntax called XACML to implement ABAC, which we regarded as both overcomplicated and painfully verbose. Also, XACML allows defining rules which can deny access; we prefer a “default deny” approach, where the absence of rules is what denies access, as this makes rule evaluation much simpler.↩︎
SQLite is not recommended for production, unless the tenant’s data is read-only. Multiple attempts to write to the schema would not perform well, as SQLite locks the entire database file for writing.↩︎